注:本人也只会一些简单的爬虫,然后只要是用于介绍爬虫爬取逻辑。
我搞的项目地址: suyihang15/Crawl: 一个简单的爬虫示例
代码操作步骤
1、导入上网工具,让你的程序可以连接上网(主要是用于访问,因为其实爬虫也要像人一样去访问网站才行)
import requests
2、填入你要爬的网站(你要爬哪个网站就填啥)
url = “爬取的网站的完整网址”
3、做一个简单的伪装(就让网站认为你是一个真人)
head = {“User-Agent”:”Mozilla/5.0″}
4、对你要爬的网站发送请求
res = requests.get(url,headers=head)
5、调整文字格式,防止爬取出来的是乱码。
res.encoding = res.apparent_encoding
6、获取网站上的资源内容
content = res.text
7、把你要的资源打印出来
print(content)
但是下面的东西搞不了
1. 网站需要登录账号
必须登录才能看的内容,爬虫直接进不去,爬不到,我这个只能爬取你能看见的内容
2. 网站开启反爬虫防护
网站识别出你是程序,直接拒绝访问,不给你数据,因为网上有很多乱爬的,怕给网站服务器崩了。
3. 内容是动态加载出来的
往下滑动页面才出现的内容,普通爬虫抓取不到,你需要根据你自己所学去搞了
4. 爬虫访问速度太快
一秒频繁访问很多次,网站直接拉黑你的网络IP,这就是为什么一般要限制爬取速度的原因
5. 资源被加密隐藏
图片、视频真实地址被藏起来、加密处理,爬虫找不到,这里还是你要对其对应的网站做对应处理
6. 需要浏览记录、身份验证
没有用户浏览信息,无法获取内容
7. 网站明确禁止爬虫抓取
我们再怎么说也要遵守法律不要乱爬资源,有句话说的好,爬虫学的好,牢饭少不了,你一快了,就会变成网络攻击了。
爬虫的运行逻辑
1、导入可以上网的库(我这里用的是requests)
2、伪装好自己(不然就被拦截了)
3、发送请求(让其可以让你访问网站)
4、设置好一些基础的(比如要的格式,要爬什么资源)
5、输出(让你爬取的资源打印出来)
补充
import time #导入时间库,设置时间的
time.sleep(时间) #设置每次访问时间
做一个简单的for循环,这个应该理解吧
for i in range(次数):
res = requests.get(url, headers=head)
print(content)
免责声明:
本文章就只是介绍如何爬取资源,只是一个简单的逻辑,请不要利用爬虫做任何违法的行为,本人遵守法律,如有任何问题,本人该不负责。
爬取示例(爬取的是本人的博客网站)
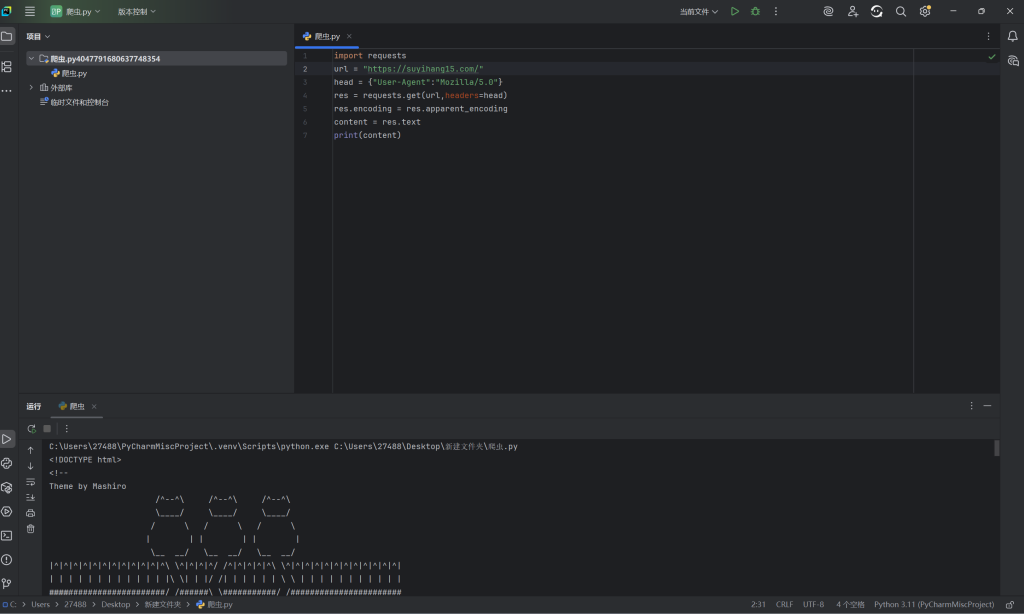
其爬取出的东西就会在输出栏打印出来,后面根据你自己的需要更改。
总结:大致就是这些,当然,这就是个引子,如果你要详细的去学,还要学的东西有很多,本人就会一些皮毛,反正大致的逻辑就是这样,到对应的网站你就要具体问题具体分析。
还有网络上我们用浏览器看到的网站基本上都是利用爬虫爬取的,可以说没有爬虫,基本上就没有浏览器,但是,他们一般都要遵守robots.txt协议,这是最基本的规则,它可以让浏览器是否收录该网站,你可以仔细看看其中的条款,这就是一般网站是否要浏览器上可以搜索到网站信息的根本,我们也应该遵守该协议,我觉得这是互联网最基本的准则。